Lighting@刘迎光
相信了,才有可能遇见,不相信,也许只会是擦肩而过!
Toggle navigation
Lighting@刘迎光
首页
IT技术
微服务(IT)
技术问答
OpenBI
读书笔记
公众号【今日脑图】
关于我
自媒体
归档
标签
《数据仓库》阅读记录
数据仓库
DataWarehouse
2017-04-20 12:49:46
1268
lightingfire
数据仓库
DataWarehouse
# 数据仓库的基础概念 ## 面向主题 从下图可以看出,面向主题中的主题,可以看做我们常常设计维度的时候部分维度的抽象,如下图中,顾客活动和和顾客其实都是维度,但是是不同的特殊维度。 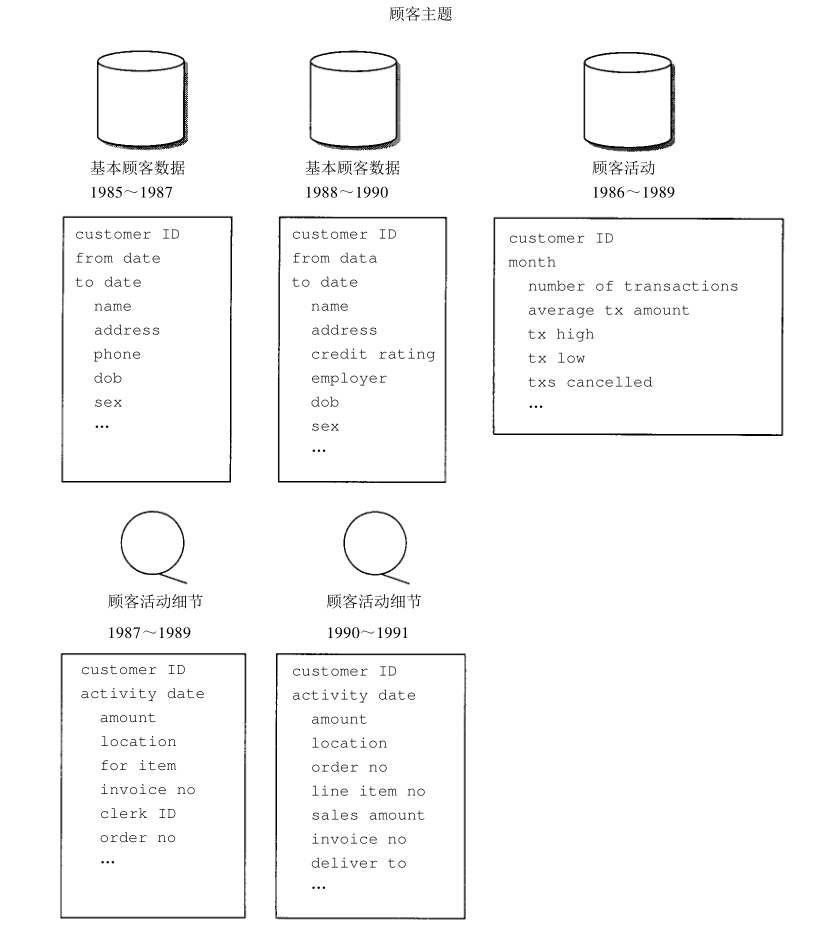 ## 粒度 数据仓库中粒度化的数据是重用性的关键,因为它可以由众多的用户以不同方式使用。 ### 举例: 就拿我们常用的日期维度来说,我们常常把日期维度分为“年、季度、月、周、日、小时”等,那么这里的“年、季度、月、周、日、小时”就是不同的六个粒度(相对时间上的),假设数据仓库中在时间上的粒度是日,那么就需要建立以日为最小分组统计的聚合表,在这个聚合表中,最小可以看到以日为单位的统计数据。 如果要查看周、月、季度、年的相关统计数据,就可以基于日的数据来进行进一步统计及计算。那么问题来了,如果我要看小时的数据怎么办,没有办法的,除非设计的最小粒度为小时。这就是数据的重用性。 当然,同一数据仓库中,对于同一纬度的不同level,也可以有相应粒度对应的数据,但是这样会造成数据的冗余;当然,也可以根据具体使用情景,决定是否需要这样的冗余(原书中说的是双重粒度,这里我更喜欢称为是多重粒度)。 ## 数据的异构 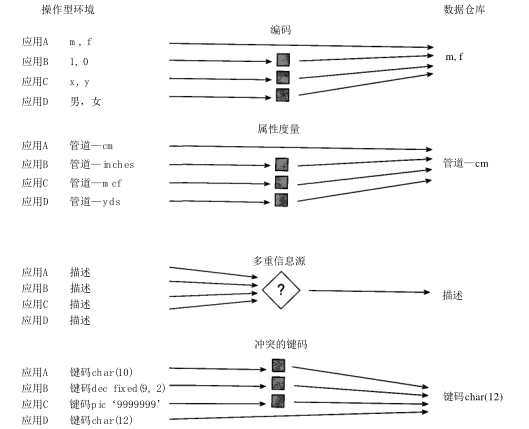 ## 报表是否必须在数据仓库中进行 这个答案是不一定的 1. 有些操作型报表需要的数据,在数据仓库中并不存在。 2. 即使操作型报表需要的数据,都会在数据仓库中存在,但是也许当时操作型数据库用到数据的同时,数据并未被归集到DS中(一般DS中的数据并不是实时的,而是定期通过ETL处理的),那么就会出现时数据错乱。 ## 数据仓库中的错误数据如何处理 ### 错误是难免的,一般错误出现的情况有如下几种: 1. ETL过程设计错误 2. 操作型数据库中的数据是先write后update的数据 ### 解决办法 1. 进入数据仓库中,找到相应的数据条目,将基础数据修改,并需要彻底找到所影响的条目,全部重新计算,否则会造成数据失去一致性。 2. 加入修正条目,即先加入一条数据,抵消之前的错误数据,再插入正确的数据,然后将受到影响的条目全部重新计算,但是这样会造成一个问题,也许修正后,根本无法再进行重新计算。 # 设计数据仓库 ## 元数据 元数据在数据仓库的上层,并且记录数据仓库中对象的位置。典型地,元数据记录: 1. 程序员所知的数据结构。 2. D S S分析员所知的数据结构。 3. 数据仓库的源数据。 4. 数据加入数据仓库时的转换。 5. 数据模型。 6. 数据模型和数据仓库的关系。 7. 抽取数据的历史记录。 ## 数据周期---时间间隔 所谓数据周期是指从操作型环境数据发生改变起,到这个变化反映到数据仓库中所用的时间。 简单来说,就我们使用的信用卡,你可以查看到你的消费详单,但是你会看到很多当天的消费,都是“未入账”的状态。其实大多数银行都是24小时入账一次。然后反映到到数据仓库中。 原则上从操作型环境知道数据的改变到这个变化反映到数据仓库中至少应该经历 24小时。当然也不是必须的,可以根据业务作出适应的调整。 不建议把时间间隔设置太短。有如下原因: 1. 如果操作型环境与数据仓库相互之间结合得越紧密,那么所需的费用就越昂贵,技术也越复杂 2. 更有说服力的一个原因是,时间间隔给环境附加了一个特殊的限制。间隔 2 4小时,使得在数据仓库中不必做操作型处理;在操作型环境中不必做数据仓库处理。 3. 转入数据仓库之前,数据能达到稳定 ## 转换和继承的复杂性 1. 从原始操作型环境到数据仓库环境的数据抽取需要实现技术上的变化。如数据库的改变等。 2. 从操作型环境中选择数据是非常复杂的。有时候需要通过多个条件来判断一个数据是否可以抽取处理。 3. 操作型环境中的输入关键字在输出到数据仓库之前往往需要重新建立。 4. 数据被重新格式化 5. 数据转换为可接受的形式。 6. 存在多个输入数据源。 7. 当存在多个输入文件时,进行文件合并之前可能要首先进行关键字解析,也可能需要重新排序等。 8. 可能会产生多个输出结果。 9. 为抽取过程选择输入的数据时,效率通常是一个问题。 10. 经常需要进行数据的汇总。 11. 在数据元素从操作型环境转移到数据仓库的过程中,应该对数据元素的重命名操作进行跟踪。 12. 需要读取的输入记录具有以异常的或非标准的格式。 13. 定长记录。 14. 变长记录。 15. 出现不定。 16. 出现子句。 17. 必须理解业务逻辑才能判断如何写入。 18. 必须进行数据格式转换。 19. 必须考虑到进行大容量输入的问题。 20. 数据仓库的设计必须符合企业数据模型。 21. 数据仓库反映的是对信息的历史需求。 22. 数据仓库着眼于企业的信息化需求。 23. 必须考虑将要进入数据仓库的新创建的输出文件的传输问题。 ## 管理大量数据 数据仓库中需要进行管理的数据的规模是一个重要问题,常常会造成效率问题,有如下常用的解决办法: 1. 建立概要记录(即创建适合应用场景粒度的聚合数据),缺点是不够细致,所以概要记录必须足够灵活。 ## 数据仓库数据的直接操作型访问 操作型环境可以直接访问数据仓库来获取数据,但是有一些严格的、不能妥协的限制: 1. 这个请求必须能够忍受冗长的响应时间。 2. 对数据的请求必须是最小量的 3. 管理数据仓库所用到��技术必须与管理操作型环境所用到的技术一直。 4. 从数据仓库取得的、准备传输到操作型环的数据必须不做(或者仅需最小量的)格式化。 > by 刘迎光@萤火虫工作室 > OpenBI交流群:495266201 > MicroService 微服务交流群:217722918 > mail: liuyg#liuyingguang.cn > 博主首页(==防止爬虫==):http://blog.liuyingguang.cn
Pre:
微服务指南走北(五):什么样的服务才可以说是微服务?
Next:
微服务指南走北(四):你不愿意做微服务架构的十个理由
Table of content
